On February 18th, the DeepSeek team released a paper introducing a new attention mechanism called NSA (Natively Sparse Attention).
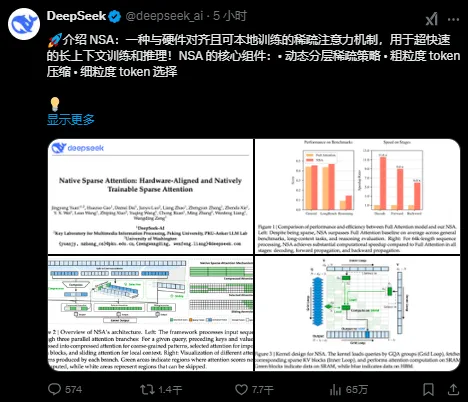
NSA is specifically designed for long text training and inference. By leveraging dynamic hierarchical sparse strategies and other methods, through the optimization design tailored for modern hardware, it significantly enhances the performance of traditional AI models during training and inference, particularly improving the inference capabilities for long contexts. It not only ensures performance but also boosts inference speed and effectively reduces the pre-training cost.
The founder of DeepSeek, Liang Wenfeng, was among the authors of the paper and ranked the second to last in the author list.

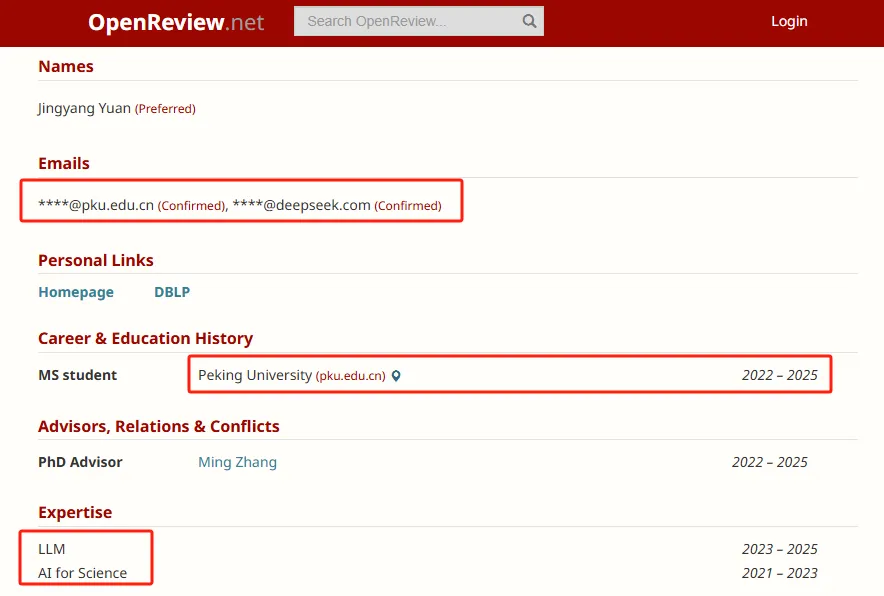
Other researchers are from DeepSeek, Peking University and the University of Washington. The first author Jingyang Yuan completed this research during her internship at DeepSeek.
According to the information, Yuan Jingyang is currently a master’s student at Peking University. His research fields include large language models (LLM) and the application of artificial intelligence in science (AI for Science). He is one of the main authors of the DeepSeek-V3 technical report and also participated in the DeepSeek-R1 project, which aims to enhance the reasoning ability of large language models through reinforcement learning.
In the paper, the DeepSeek team said that with the development of large language models, long-context modeling has become more and more important, but the computational complexity of the traditional attention mechanism has increased by the square level with the increase of sequence length, which has become a key bottleneck restricting the development of models.
NSA is a technology path for efficient handling of long-context tasks, and its core innovations are:
1) Dynamic hierarchical sparse strategy: Combining coarse-grained token compression and fine-grained token selection, it not only ensures global context awareness, but also takes into account the accuracy of local information.
2) Hardware alignment and end-to-end training: Through the algorithm design and hardware optimization of arithmetic intensity balance, the computing speed is significantly improved, and end-to-end training is supported, reducing the amount of pre-training computation.
Experiments show that NSA not only performs well in general tasks and long-context tasks, but also shows strong potential in complex tasks such as chain reasoning, and the inference speed is accelerated. In general-purpose benchmarks, long text processing, and instruction-based inference tasks, NSA can reach or even exceed the level of traditional full attention models, and it rarely applies sparsity in the training phase in a cost-effective way, and achieves significant speed improvement in training and pushing scenarios, especially in the decoding stage by up to 11.6 times.
Through efficient long sequence processing capabilities, NSA enables the model to directly process entire books, code repositories, or multiple rounds of conversations (such as the 1,000-round customer service scenario), expanding the application boundaries of large language models in document analysis, code generation, complex reasoning, and other fields. For example, Gemini 1.5 Pro has demonstrated the potential for long contexts, and the NSA can further reduce the training and inference costs of such models.